Actions and adaptability have opened the opportunities to explore the depths of Generative AI, where business touchpoints are multiplied by 5X.
Most businesses are witnessing the potential of Generative AI and investing so much into it to lead the show. In this demanding and competitive portfolio, companies are applying generative AI models into their cloud ecosystem for building the futuristic enterprise applications and, Oracle is no exception.
With a comprehensive set of Generative AI fully managed services where versatile language models are integrated for a wide range of use cases, it is now the paradigm shift to process many tasks at faster rates. The leading models for Oracle Cloud Infrastructure (OCI) are tailored for business use cases with a customer-focused holistic strategy, driving operational excellence.
Here is a deep dive into the concepts of OCI generative AI service for a clear understanding of how these models work for enterprises, offering unparalleled advantages:
Supported Large Language Models (LLMs) in OCI Generative AI Service
Oracle Cloud Infrastructure (OCI) Generative AI offers great support for LLMs including – Cohere (Command series), Meta’s Llama 2 – enabling users to leverage its advantages within the platform for different text generation and processing tasks. These models extend their support to multilingual capabilities across over 100 languages.
LLM | Features |
Command model by Cohere | Model Parameters: 52 billion Context Window: 4096 tokens Usage: Text Generation, Chat, Text Summarization |
Command Light Model by Cohere | Model Parameters: 6billion Context Window: 4096 tokens Usage: Text Generation, Chat, Text Summarization Smaller, faster version of command model |
Llama2 70b chat Model by Meta | Model Parameters: 70 billion Context Window: 4096 tokens Usage: Text Generation, Chat |
The other supporting LLMs models include Embedding model, Embed English, and Embed English Lite by Cohere.
Apart from these LLMs, OCI Generative AI brings various LLM mechanisms for enterprises to simplify their tasks. These include:
- Token: In LLMs, token is a simple word or a punctuation. When the model functions in the playground, maximum number of output tokens can be selected, and 4 characters can be chosen per token. For example, friendship is two tokens – “friend” and “ship”.
- Penalty: A penalty is for a token when it appears frequently. The higher the penalties, the fewer the repeated tokens, leading to a more random output.
- Accuracy: The number of predictions that made right out of all the predictions refers to accuracy.
- Decoding: It is a process to generate the next probable token in the sentence.
- Greedy decoding: This will pick the highest probability word as the next token.
- Encoding: Models that convert the sequence of words into embeddings (vector representation)
- Embedding: Embeddings are a numerical representation of a piece of text / word/ sentence or a paragraph or a whole document converted to number sequences. The Generative AI embedding models change each phrase, sentence, or paragraph into an array of 384 or 1024 numbers, depending on the embedding model chosen.
- Hallucination: LLMs may generate a text which is not TRUE as per the fact, this kind of incorrect information provided in the response is called Hallucination
- Text generation models: A model that would generate the next relevant token or sequence of tokens. The below are the parameters that can be defined while using text generation model
- Temperature: A model that would generate the next relevant token or sequence of tokens. The below are the parameters that can be defined using text generation model:
- Max output tokens: This will define the number of tokens to be generated in the response.
- Top k: This is a sampling method where the model choses the next token from the top k most likely tokens. The higher value for “k” generates random output.
- Top p: A sampling method that controls the cumulative probability of the top tokens to consider for the next token. Assign p a decimal number between 0 and 1 for the probability.
Summarization Models
Summarization model can be used from the command model of Text Generation with some special parameters as described below:
- Temperature: Determines how creative the model should be. Default value is set to 1 and Max value is 5
- Length: Approximate length of the Summary. Choose the length from the options available like Short, Medium or Long.
- Format: How to display the result whether in a free form paragraph or in bullet points.
- Extractiveness: How much to reuse the provided input in the summarization
Embedding Models
Embedding models will convert the text into an embedding and store it as a vector in vector database.
Success of INFOLOBPrompt Engineering ’s Oracle Cloud Migrations
Prompt is the input provided to the LLM, whereas Prompt Engineering is to modify the input to get the relevant response. The instructions need to be given in a proper format with <INST> tags or else the result would not be appropriate. Now, to achieve this there are different ways to do as describe below:
- In-Context Learning: In Context Learning would provide few demonstrations or instructions to the LLM to complete the task requested in the prompt.
- K-Shot Prompting: Explicitly providing k no. of examples of the intended task in the prompt.
Few shots prompting is widely believed to improve the result over zero shot prompting.
- Chain of Thought: This will prompt the LLM with example and to show or emit the intermediate reasoning steps in the response.
- Zero Shot Chain of Thought: This will not provide any example to the prompt instead say one line statement.
- Least to Most: Prompt the LLM to solve the easy one first.
Step Back: Prompt the LLM to identify high level concepts pertinent to a specific task as available in the pre-trained models.
Customizing Pre-trained Models or LLMs
There are different ways to customize the pre-trained model or the LLM to get the relevant response to the prompt given by the user. The below are some of the methods used to customize LLM:
- Prompt Engineering: Prompt Engineering is one of the ways to customize the LLM by different means like In Context Learning, Few Shot Prompting, Chain of thought etc.
- Fine Tuning: Fine tuning is used to optimize the model on a smaller domain specific dataset. Recommended when the pretrained model does not perform well or you want to teach something new.
- Retrieval Augmented Generation (RAG): This would enable LLM to connect with the Knowledge base like (databases, wikis, vector databases etc) which would help in providing the grounded responses.
- Custom Model in OCI Generative AI: A pre-trained Large Language model used as base and fine-tuned with custom data to create a custom model. OCI Generative AI need a dedicated AI Cluster of type fine tuning to fine tune the model
- Model Endpoint in OCI Generative AI: A designated point in dedicated AI Cluster where a large language model can accept user request and send the response such as model’s generated text. This need a dedicated AI Cluster of type Hosting where the endpoint is created.
RAG Framework
RAG framework is made up of below components:
- Retriever: It will gather all the relevant information. It acts like a search engine and fetches all the relevant data.
- Ranker: It will evaluate and prioritize the data obtained by the retriever, based on the relevance it will rank the documents.
- Generator: This will generate the human like text from the documents or data obtained from the Ranker.
RAG Techniques
- RAG Sequence: This will search for all the documents relevant to the query and generate a cohesive response from the documents.
- RAG Token: This will search based on the keyword and this search would fetch all the documents matching the keyword.
- Semantic Search: Search based on the meaning of the query
- Dense Retrieval: Dense Retrieval will search for the documents in a vector which are near to the query.
- Reranking: Reranking is to re-rank the documents after the first search of documents.
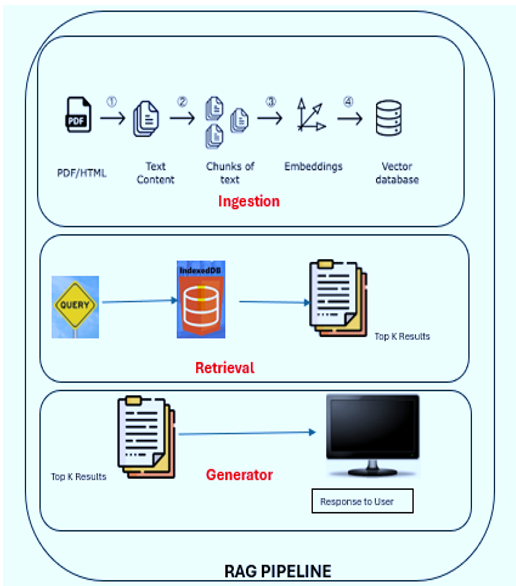
RAG Pipeline
RAG Pipeline consists of 3 steps as described in the below diagram:
Step1: Ingestion – where the data is being loaded into the vector database
Step2: Retrieval – this will search for the relevant documents.
Step 3: Generator – it will generate the human like text and responds to the user.
Lang Chain
Lang Chain is a framework for developing applications powered by language models. It offers a multitude of components that help us build LLM powered applications.
Lang Chain Components
Lang Chain components are used a build a Lang Chain application. The below are the components.
- LLMs
- Prompts
- Memory
- Chains
- Vector Stores
- Document Loaders

Image reference – https://datasciencedojo.com/newsletter/guide-to-learn-langchain/
- Lang Chain Prompt Template: Prompt templates are pre-defined recipes for generating prompts for language models.
- String Template: The template supports any number of variables, including no variables.
- Chat Prompt Template: The prompt to chat model is list of chat messages. Each chat message is associated with content and an additional parameter called role.
- Lang Chain Chains: LangChain provides framework for creating chains of components including LLMs and other type of components.
- RAG with LangChain: LLM has limited information and need to be augmented with custom data.
- RAG Plus Memory with LangChain: In addition to RAG we can utilize memory for more conversation approach.
- LangChain Memory: Ability to store information about past interactions is “memory”. Chain interacts with the memory twice in a run.
- After input but before chain execution (Read from memory)
- After core logic but before output (Write to memory)
- There are two types of memories available in LangChain – Conversation Buffer Memory and Conversation Summary Memory
- LangChain memory uses Streamlit to manage the memory for every user session.
As we set our roadmap to innovate around OCI Generative AI touchpoints, we have setup the stage for curious techno crats to understand each of these terms and components. Our research focuses primarily on Generative AI inside cloud environments to boast user experience for the applications you develop. The fully managed OCI infrastructure comes with many Generative AI features that promotes 360-degree business growth, meeting business objectives and your needs.
Generative AI isn’t just an integral part of your cloud infrastructure; it’s a strategic imperative where the capabilities and features become a game-changer for your business.
For all queries, please write to: